



The Scaling Fallacy: Bigger LLM won't lead to AGI

The scaling hypothesis has been a very … wealthy one. With people like Sam Altman (OpenAI) and Dario Amodei (Anthropic) being believers, billions of dollars have gone into making large language models (“LLMs”) like ChatGPT and Claude bigger and … BIGGER.
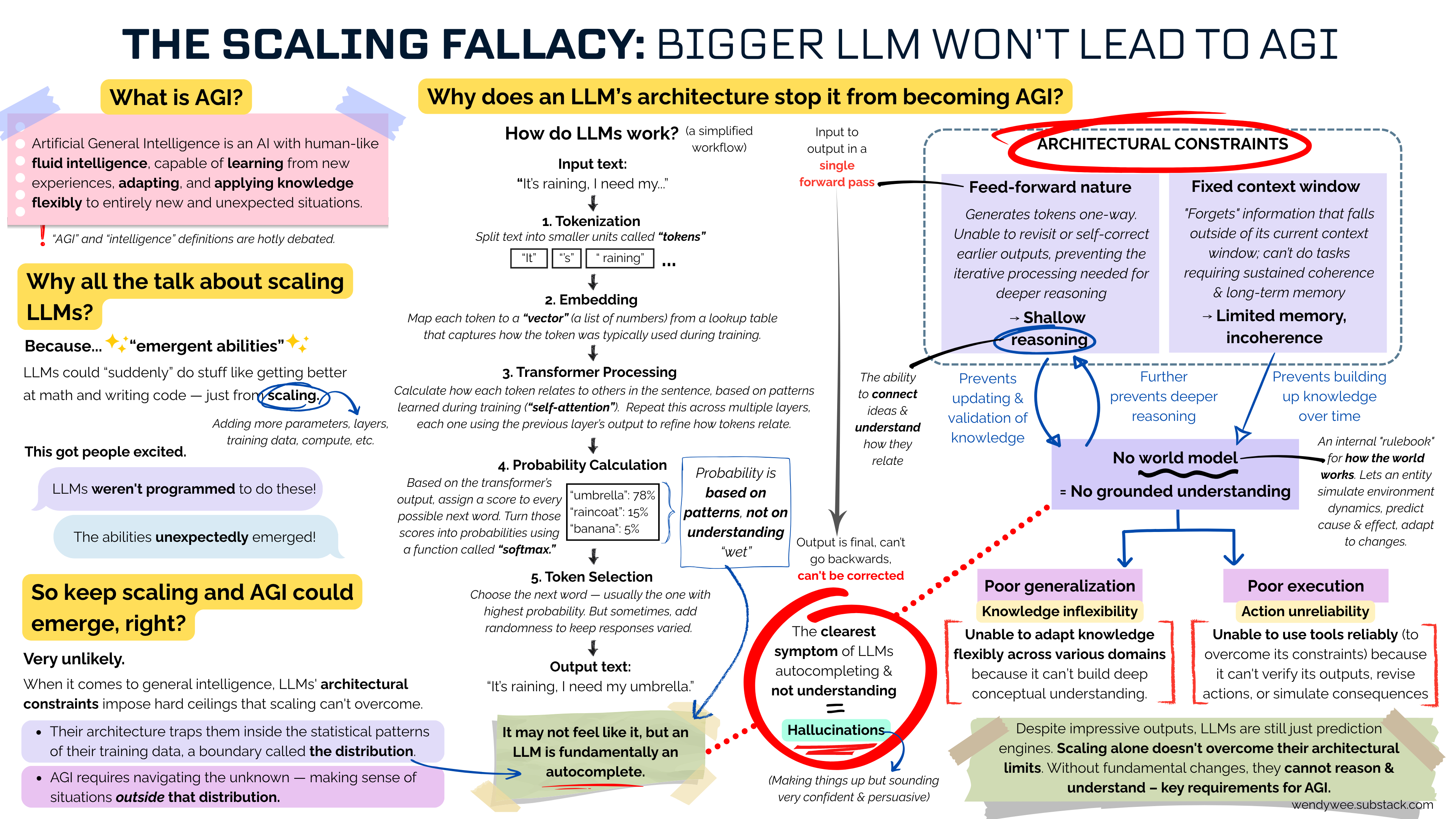
The belief is that just by feeding an LLM with more training data, parameters, compute, and other resources (“scaling”), Artificial General Intelligence (“AGI”) will eventually emerge.
This infographic explains why that is not the case.
The emergence.
As mentioned in the infographic, the excitement about scaling came about because of “emergent abilities”, where some AI experts noticed that when the LLM models became bigger, they could “suddenly” do things that smaller models couldn’t, like complex math and coding.
This sense of awe and mystery led some people to this thought process:
Scaling made LLMs more capable
More scaling = more capability
Eventually, they’ll become AGI
If you noticed, I’ve been using quotation marks for words like “emerge” and “sudden”. It’s because there are a whole other bunch of AI experts who are saying those abilities are neither “emergent” or “sudden”. Their reasons range from results not being measured properly to what’s likely happening is memorization, interpolation, or in-context learning. They kind of do make sense. If you feed an LLM billions of lines of code, you should expect that it can then generate code–because it can now statistically predict what code text comes next. It’s what LLMs do: next-token prediction.
Anyhow, TL; DR on “emergence”: As of now, the AI world is divided on not only what’s causing the “emergent abilities”, but whether the abilities are even “emergent”.
Nevertheless! The inconclusiveness of whether those observed abilities are emergent does not matter when it comes to AGI.
The fundamental reason LLMs won’t become an AGI.
AGI isn’t about just doing a single task impressively, like solving math problems or writing Python scripts. It’s about being able to adapt across tasks and domains without retraining, learning new things on the fly, and applying knowledge in novel, unstructured situations.
And as the infographic explains, for that general intelligence, the LLM architecture does not allow it.
An LLM with scaffoldings is no longer just an LLM. Stop the gaslighting.
Some of you might be annoyed by now:
“Why are you dismissing the developments addressing the limitations you’re talking about? Like retrieval-augmented generation (RAG) systems that give LLMs access to external knowledge bases, tool integration systems that let LLMs execute code and access real-time data, and so on?”
To which, I’d say:
If you include “workarounds” requiring external modules, it means you’re no longer talking about just an LLM anymore. It’s already become a larger system that has an LLM as one of its components.
And to that, you’re probably rolling your eyes because…
Everyone knows that colloquially, people would still call that system an LLM since the core engine is still a transformer-based, pre-trained LLM.
Yes, I’ve actually heard several people say this.
Why does it baffle me when people say that an LLM with all the add-ons is still called an LLM?
Well, if I accept it when they say:
LLM = LLM + memory + tools + RAG + etc.
Then, wouldn’t it be acceptable for me to call a computer a CPU? As in:
CPU = CPU + memory + I/O + storage + etc.
You might now dismiss me as just being pedantic.
Hmm, well, imagine this:
First step: Declare “LLMs will lead to AGI.”
But what they silently do is start with a base LLM that clearly lacks memory, persistent state, self-modification, etc.
Then bolt on external systems (tools, memory, retrievers, agents, etc.).
Then say: “Look! The LLM became AGI!”
Final step: Disparage the people who were calling out the architectural limitations in the first place.
That’s pure gaslighting logic.
This is not being pedantic. This is asking for an honest accounting of what systems do what work, which is basic scientific integrity.
So, the dream of “Scale LLMs and AGI will emerge” is either:
Naïve (hoping emergence will fill in architectural voids), or
Deceptive (AGI arises from a system with components beyond LLMs).
An honest framing could be:
AGI might emerge from complex AI systems that include LLMs as one component.
But perhaps that’s a much less exciting fundraising pitch than:
Scale LLMs → AGI!
This infographic is exceptional! The visual quality is phenomenal and the layout is easy to follow. In terms of content, it accurately captures key limitations of transformers that scaling simply cannot overcome. Many people could benefit from this enlightening infographic. Also, the accompanying article sets up a strong case and was a very enjoyable read.
Well done and thank you! The field needs more contributions just like this. I'm looking to your next post. Keep up the great work!